定型PDFからのテキスト抽出ツール
面倒な定型フォーマットPDFの転記作業を自動化!
取り組み内容
【課題】
- 図面や帳票など、定型フォーマットのPDFから必要な情報を転記する作業が発生していた。
- 手作業による転記は、作業時間が長く、ミスも発生しやすい。
- 特にデータ量が多い場合、本来業務へのリソース圧迫が課題となっていた。
- また、PDFの種類(内部テキスト型 or 画像型)によって適切な処理方法を選ぶ必要があり、汎用ツールでは対応しきれなかった。
【解決策】
アプローチの整理
対象となるPDFの性質に応じて、
2種類の専用ツールを用意し、適切に使い分ける運用とした。
| タイプ | 処理方法 | 適用対象 |
|---|---|---|
| テキストデータ内包型PDF (テキストの選択ができる場合) | 内部テキストデータを直接抽出 | デジタル生成PDF(CAD、Office文書など) |
| 画像型PDF | OCR(光学文字認識)でテキスト化 | スキャンPDF、画像埋込PDF |
※ 対象PDFを事前に分析し、適切なツールを選択して処理
解決策の詳細
① テキスト内包型PDF用ツール
- PDF内部に含まれるテキストデータを高速・高精度で抽出
- PDFファイルが保管されているフォルダを選ぶEXE型ツール
- 抽出結果はCSV形式に変換し、後工程(Excel等)での活用が容易
② 画像型PDF用OCRツール
- スキャンデータに対しOCR解析を行い、定型フォーマットに基づいてテキストを抽出
- 軽微な認識補正が必要な場合もあるが、大幅な手作業削減が可能
- 抽出結果は同様にCSV形式で出力
ツール別:メリット・デメリット比較
| タイプ | メリット | デメリット |
|---|---|---|
| テキストデータ内包型PDFツール | – 高速・高精度にテキスト抽出可能 – 誤認識なし – 軽量ツールでサクサク動作 | – テキストデータが内包されていないPDFには使用不可 |
| 画像型PDF用OCRツール | – スキャンデータからもテキスト化可能 – 手作業の代替ができる | – OCR誤認識リスクあり – 処理速度は内包型よりやや遅い |
実際の人力作業イメージ(参考)
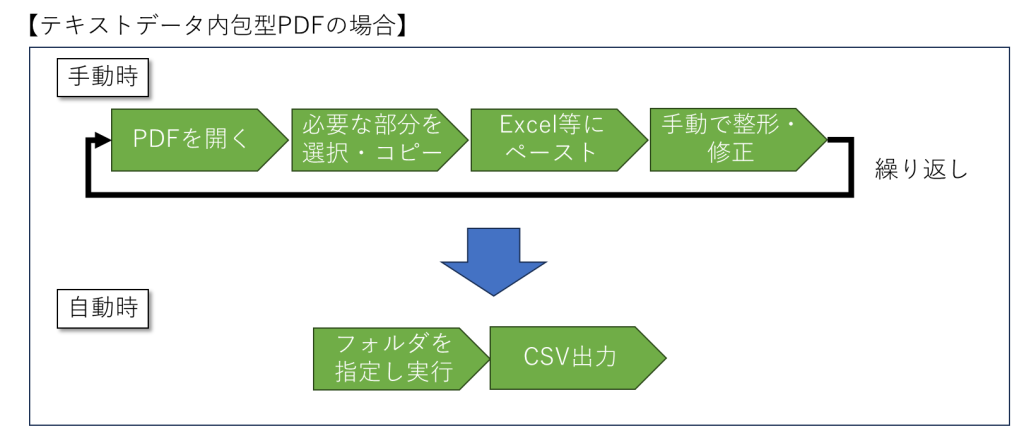
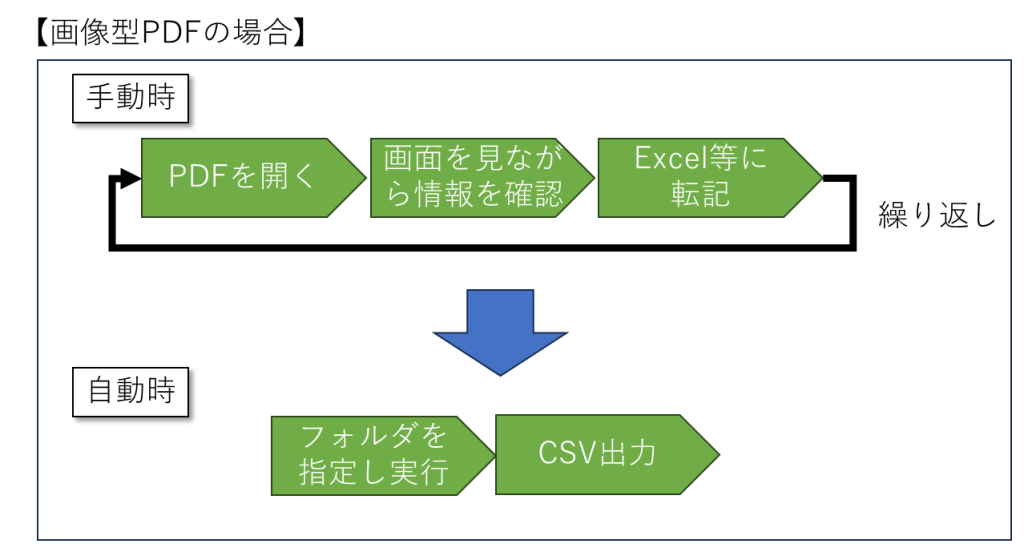
手作業による煩雑なコピー&ペースト工程を、ツールによって一括処理・CSV出力に置き換えることで、大幅な作業効率化を実現しています。
得られた効果
- 手作業による転記ミスが大幅に減少
- 作業時間を最大90%以上短縮
- テキストデータ内包型の場合、1秒以下/1ファイル
- OCR型の場合、数秒/1ファイル
- CSV出力によって、後工程(Excel処理・データベース投入)もスムーズに
- 社員が本来集中すべき業務にリソースを振り向けられるようになった
利用時の注意点
汎用性よりも「現場作業に合わせた確実な運用」を重視して設計されています。
対象PDFを事前に確認し、適切なツール(テキスト抽出型 or OCR型)を選択する必要があります。
OCR型ツールの場合は、認識精度チェック・軽微な修正作業が必要になる場合があります。
本ツールは完全な汎用型ではありません。
対象とする定型フォーマットに最適化して開発される専用ツールです。
そのため、新しいフォーマットに対応する場合には、プログラム側のカスタマイズ対応が必要となります。
開発背景・想い
現場では、定型フォーマットPDFからの情報転記に多くの時間と労力が費やされていました。
単純作業の繰り返しは、ミスやストレスを生み出し、本来注力すべき業務の妨げになっていました。
また、PDF内部構造の違い(テキストデータの有無)によって、単純な汎用ツールでは十分な対応ができないという問題もありました。
「誰でも確実に、できるだけ早く正確に情報を取り出せる仕組みを作りたい」
そんな想いから、対象PDFに合わせた専用ツール群を開発し、作業負荷の抜本的な軽減を実現しました。